死锁是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种互相等待的现象。若无外力作用,事务都将无法推进下去。如果程序是串行的,那么不可能发生死锁。死锁只存在于并发的情况,而数据库本身就是一个并发运行的程序,因此可能会发生死锁。
解决死锁问题最简单的方式是不要有等待,将任何的等待都转化为回滚,并且事务重新开始。毫无疑问,这的确可以避免死锁问题的产生。然而在线上环境中,这可能导致并发性能的下降,甚至任何一个事务都不能进行。而这所带来的问题远比死锁问题更为严重,因为这很难被发现并且浪费资源。
超时回滚
解决死锁问题的另一种方法是超时,即当两个事务互相等待时,当一个等待时间超过设置的某一阈值时,其中一个事务进行回滚,另一个等待的事务就能继续进行。在InnoDB存储引擎中,参数innodb_lock_wait_timeout用来设置超时的时间。
超时机制虽然简单,但是其仅通过超时后对事务进行回滚的方式来处理,或者说其是根据FIFO的顺序选择回滚对象。但若超时的事务所占权重比较大,如事务操作更新了很多行,占用了较多的undo log,这时采用FIFO的方式,就显得不合适了,因为回滚这个事务的时间相对另一个事务所占用的时间可能会很多。
Wait-for graph
除了超时机制,当前数据库还都普遍采用wait-for graph(等待图)的方式来进行死锁检测。较之超时的解决方案,这是一种更为主动的死锁检测方式。InnoDB存储引擎也采用的这种方式。wait-for graph要求数据库保存以下两种信息:
- 锁的信息链表
- 事务等待链表
通过上述链表可以构造出一张图,而在这个图中若存在回路,就代表存在死锁,因此资源间相互发生等待。在wait-for graph中,事务为图中的节点。而在图中,事务T1指向T2边的定义为:
- 事务T1等待事务T2所占用的资源
- 事务T1最终等待T2所占用的资源,也就是事务之间在等待相同的资源,而事务T1发生在事务T2的后面
举个例子,当前数据库事务和锁的状态如下图所示
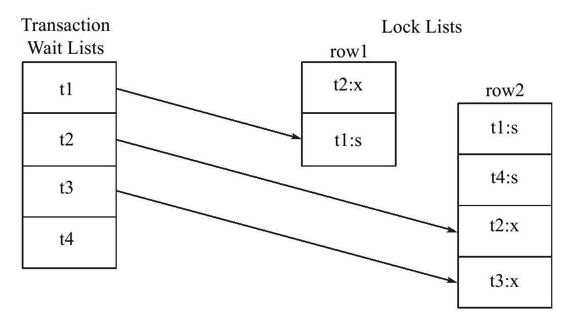
在Transaction Wait Lists中可以看到共有4个事务t1、t2、t3、t4,故在wait-for graph中应有4个节点。而事务t2对row1占用x锁,事务t1对row2占用s锁。事务t1需要等待事务t2中row1的资源,因此在wait-for graph中有条边从节点t1指向节点t2。事务t2需要等待事务t1、t4所占用的row2对象,故而存在节点t2到节点t1、t4的边。同样,存在节点t3到节点t1、t2、t4的边,因此最终的wait-for graph如图
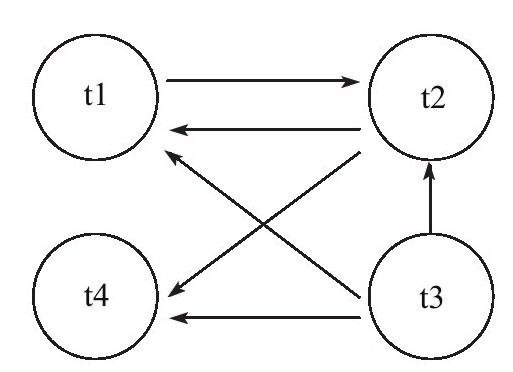
可以发现存在回路(t1,t2),因此存在死锁。通过上述的介绍,可以发现wait-for graph是一种较为主动的死锁检测机制,在每个事务请求锁并发生等待时都会判断是否存在回路,若存在则有死锁,通常来说InnoDB存储引擎选择回滚undo量最小的事务。
wait-for graph的死锁检测通常采用深度优先的算法实现,在InnoDB1.2版本之前,都是采用递归方式实现。而从1.2版本开始,对wait-for graph的死锁检测进行了优化,将递归用非递归的方式实现,从而进一步提高了InnoDB存储引擎的性能。
死锁的示例
死锁一种经典的情况是A等待B,B在等待A,这种死锁问题被称为AB-BA死锁。下表展示了这种死锁。
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | select * from t where a=1 for update; | |
| 2 | select * from t where a=2 for update; | |
| 3 | select * from t where a=2 for update; # waiting | |
| 4 | select * from t where a=1 for update; # Deadlock found |
此外还存在另一种死锁,即当前事务持有了待插入记录的下一个记录的X锁,但是在等待队列中存在一个S锁的请求,则可能会发生死锁。
| 时间 | 会话A | 会话B |
|---|---|---|
| 1 | select * from t where a=4 for update; | |
| 2 | select * from t where a<=4 lock in share mode;# waiting | |
| 3 | insert into t values(3); # Deadlock found, rollback | |
| 4 | # Get lock |
References
[1] 姜承尧 《MySQL技术内幕 : InnoDB存储引擎(第2版) 》